")
")
Програмісти у своїй професійній діяльності широко використовують структури даних для зручного зберігання інформації. У цій статті ми поговоримо про те, якими способами можна зберігати дані й чому взагалі це потрібно знати програмісту.
Почнемо з того, що 1976 року швейцарський учений Ніколас Вірт написав книгу про те, що «алгоритми + структури = програми». Про важливість алгоритмів ми з вами знаємо і неодноразово обговорювали цю тему на сторінках нашого журналу.

То що таке структури даних?
Погуглимо? «Структури даних – це контейнери, які зберігають дані у певному форматі». Які структури бувають?
- Масиви
«Масив — це найпростіша структура даних, що широко використовується. Інші структури даних, такі як стеки та черги, є похідними від масивів».
Чому не можна зберігати всі дані в масивах чи їх комбінаціях, хай навіть й грамотних?
Річ у тому, що не у всіх завданнях буває зручно зберігати дані в масиві. Наприклад, нехай буде наступне завдання: зробити простенький словник, якщо є слова однією мовою та їхній відповідний переклад іншою мовою. Нам потрібно реалізувати додавання, видалення слів та пошук перекладу потрібного слова у наявному словнику.
Так от виявляється, що, якщо реалізувати такий словничок за допомогою масивів (можете спробувати — це гарна вправа), то буде все добре, тільки доти, поки слів не стане досить багато (скажімо, мільйон). Тоді й розпочнуться проблеми зі швидкістю роботи цього словника. Погодьтеся, що чекати по кілька (а може навіть кілька десятків) хвилин для того, щоб знайти переклад потрібного слова, якось не дуже хочеться. Тут ми й приходимо в глухий кут. Як це можна зробити швидше?
- Дерева
А якщо я скажу, що існує структура даних, яка допомагає робити всі ці операції (навіть якщо у нас будуть десятки мільйонів слів) за частки секунди?
Запитайте: «Яка»? Відповідь — збалансовані бінарні дерева пошуку.
Десь ми вже про них чули, га? Так, тому що на першому курсі про них точно розповідали, а ще вони згадувалися в одній із наших попередніх статей. Хто не бачив, обов'язково подивіться «Джентльменський набір програміста. Частина 1».
Давайте не будемо вдаватися до деталей реалізації цієї структури даних, тому що про неї є дуже багато інформації в інтернеті (Stack Overflow і Geek For Geeks — вам на допомогу). До речі, у багатьох мовах програмування вбудовані в стандартну бібліотеку класів словники (наприклад, std::map в C++) та множини (std::set) реалізовані саме як збалансовані бінарні дерева пошуку.
Окей, які ще є структури даних і для яких завдань вони використовуються?
- Динамічні масиви
Простий приклад динамічного масиву — це std::vector у С++ або list у Python. Вони мають всі ті ж властивості масиву плюс, ще здатні динамічно розширяться при додаванні нових елементів.
Що це означає?
Тобто для того, щоб створити звичайний масив, нам треба заздалегідь знати його розмір, і ми зможемо зберігати в ньому рівно стільки елементів, скільком виділили місця спочатку (більше не можна). А якщо ми не знаємо скільки нам потрібно буде зберігати елементів, то тут на допомогу приходять динамічні масиви, здатні змінювати свій розмір в рантаймі. Як уже говорилося, вони мають ті ж властивості, що і звичайні та плюс деякі фішки, і до того ж працюють майже так само швидко, як і звичайні масиви.
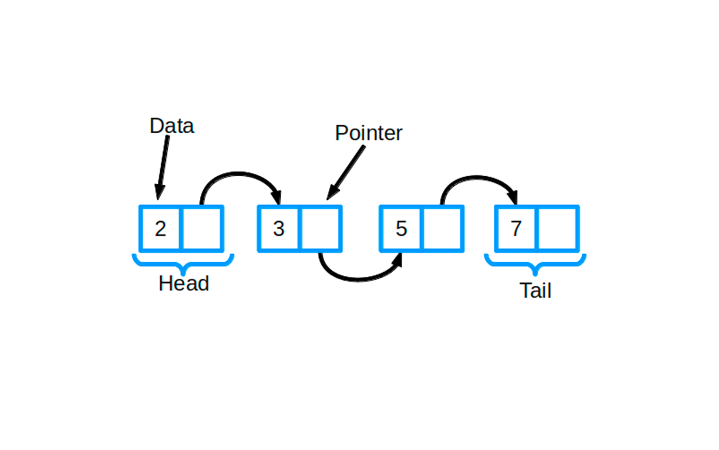
- Списки
Як знаємо, видаляти елемент з кінця масиву можна швидко, а ось із середини — ні, оскільки після нам доводиться щоразу зрушувати всі елементи, що видалялися ліворуч. Аналогічно і з додаванням до середини. Перевага списків над масивами полягає в тому, що видалення/додавання в середину списку буде працювати так само швидко, як видалення/додавання елемента в кінець. Проте за отриману перевагу нам доводиться і чимось заплатити: звернення до елементів списку за індексом тепер буде тривалим. Але якщо завдання не передбачає звернення до елементів, а полягає лише у зберіганні елементів із постійним оновленням значень, то використання списків тут буде якраз.
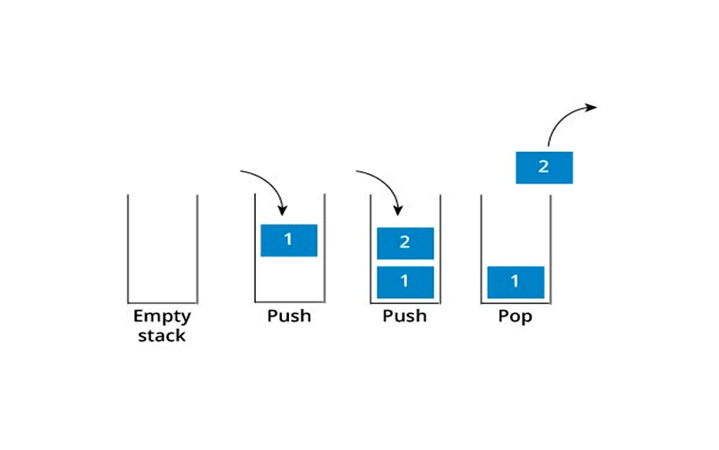
- Стеки та черги
З чергою все просто: уявіть звичайну чергу до магазину. Коли нова людина стає в чергу, вона йде в її кінець. А коли каса вкотре звільняється, то вона обслуговує найпершого покупця, який стоїть у черзі. Абсолютно аналогічно працює структура даних під назвою «черга». Коли її застосовувати? Коли порядок обробки елементів у задачі аж надто нагадує звичайну магазинну чергу.
Зі стеками все теж не складно. Уявіть собі, що ми миємо посуд і складаємо помиті тарілки в стопку. Ще одну помиту тарілку ми кладемо на верх стопки, а коли нам потрібно буде ці тарілки розкласти на столі, то ми будемо витягувати зі стопки саму верхню тарілку. Точно за таким принципом працює стек. Він застосовується у різних завданнях, і навіть ідея стека широко використовують в організації комп'ютерних обчислень. Наприклад, усі параметри функції, локальні змінні та інша інформація, пов'язана з функціями програми, знаходяться на стеку викликів.
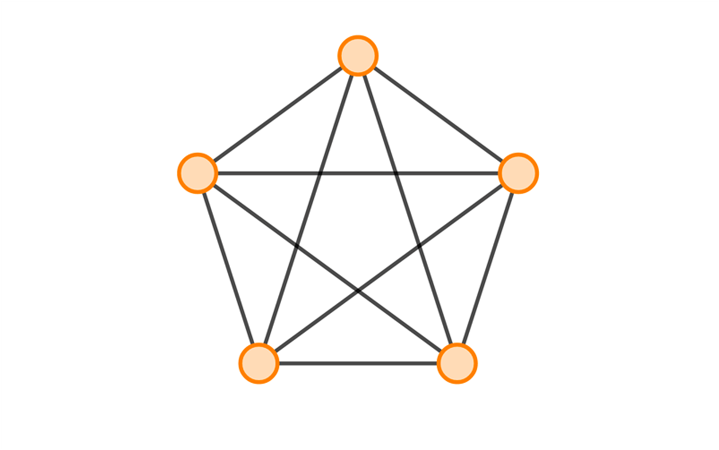
- Графи
Уявімо міста та дороги між ними. Ось вам і найпростіший приклад графа. Насправді графи широко використовуються в програмуванні в різних завданнях, згадаємо хоча б про карти й пошук найкоротших шляхів між точками. У дискретній математиці є навіть цілий розділ, відведений спеціально для вивчення цієї структури даних та супутніх алгоритмів — теорія графів. В цілому, нічого надскладного в роботі з графами немає, за винятком лише, мабуть, різноманіття різного наявного матеріалу, що робить навчання досить довгим.
Про всі ці структури даних можна почитати, звичайно, в інтернеті, благо інформації для вивчення дуже багато.
Бажаємо успіхів у освоєнні матеріалу!
Олег Топорков





