")
")
Чи знаєте ви, що розробники насправді застосовують щодня, навіть не замислюючись над цим? То що потрібно хорошому програмісту чи тим, хто хоче ним стати? Представляємо вам добірку musthave на шляху до успішного розробника.
Йтиметься, як ви вже здогадалися, про алгоритми, які повинен знати кожен програміст, який поважає себе, щоб не бігти в гугл щоразу, коли потрібно зробити щось нетривіальне (про важливість цих знань у попередній статті на цю тему).
- Бінарний (двійковий) пошук
Так-так, це саме той алгоритм, який, за статистикою, не можуть правильно реалізувати майже 75% програмістів. І це дуже сумно, адже алгоритм за своєю суттю дуже простий, а до того ж дуже корисний.
Для тих, хто раптом не знає, навіщо він потрібний, ось невелике роз'яснення.
Припустимо, Петя загадав число в межах від 1 до мільярда, а наше завдання його відгадати. Як би ми це зробили?
Послідовно називати числа дуже довго. Тому зробімо ось що:
- Спочатку візьмемо число, що дорівнює медіані (просто серединці) нашого відрізка, тобто пів мільярда.
Скажімо його Пете і запитаємо про те, де знаходиться його загадане число: лівіше (менше) половини мільярда, рівне або більше (при цьому домовимося, що Петя грає чесно і не бреше).
- Відповідно, як тільки дізнаємося його відповідь на наше запитання, одразу скорочуємо область пошуку вдвічі, а це дуже багато!
- А далі повторюватимемо описані дії стільки разів, скільки потрібно.
А потрібно насправді зовсім небагато: двійковий логарифм від мільярда операцій, що лише 30.Вдумайтеся ми лише за 30 кроків (у гіршому випадку) зможемо відгадати будь-яке число на такому величезному відрізку.
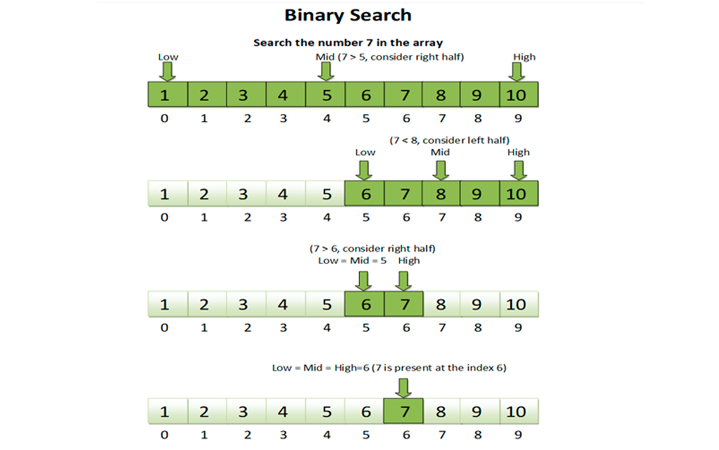
В цілому область застосування бінарного пошуку дуже велика і в основному його використовують, коли потрібно щось швидко знайти на впорядкованих (відсортованих) даних.
- Сортування
Здається навіщо знати сортування, якщо у всіх мовах вже давно є вбудовані «розумні» сортування. Відповідь проста: щоб розуміти, як реалізовувати складніші свої алгоритми та вміти використовувати хитрощі, які закладені в основи деяких сортувань.
Наприклад, сортування купою (одне з оптимальних сортувань) використовує таку структуру даних, яка, як не дивно, називається купа. По суті, це просто вид двійкового дерева. Так ось, вивчивши те, як влаштоване дане сортування, можна також дізнатися багато всього нового, не пов'язаного безпосередньо з самим сортуванням, в цьому випадку нову структуру даних. Тому що більше ви знаєте сортувань, то краще.
А з чого почати, адже сортувань так багато?
Почати можна із простого. Ось невеликий список нескладних сортувань:
- сортування бульбашкою;
- сортування злиттям;
- сортування вставками;
- сортування купою;
- швидке сортування;
- блокове сортування;
Ознайомитися з реалізаціями цих сортувань можна, наприклад, Geek For Geeks.
- Алгоритми на динаміку
Цікавий факт: даних алгоритмів разів у 10 (а може й у 20) більше, ніж алгоритмів сортувань. А пов'язано це з тим, що ідея, яку вам надає динамічне програмування (ДП), дуже підходить для вирішення просто колосальної кількості різних завдань. І це був перший аргумент, чому варто розібратися із ДП.
Другий аргумент аналогічний тому, що ми говорили про сортування, а третій у тому, що динамічне програмування дуже класно розвиває мислення.
Не питайте, чому, просто спробуйте розібратися з деякими завданнями. Список завдань, з яких можна розпочати:
- завдання про коника;
- завдання про черепашку;
- рюкзак;
- найбільша наростальна підпослідовність;
- найбільша загальна підпослідовність;
Як і раніше, деякі завдання є на тому ж GeekForGeeks або ж можна знайти їх розбори в YouTube.
- Обходи двійкових дерев пошуку
Сподіваємося, всі читачі знайомі з деревами (не з тими, що зростають на вулиці). Для першокурсників (не всіх) та тих, хто пропустив стандартний курс алгоритмів та структур даних, пояснимо: дерево — це така структура даних, яка зберігає у своєму вузлі якусь корисну інформацію, а також посилання на своїх дітей (інші вузли). На малюнку нижче ми наводимо приклад бінарного дерева (у кожного вузла є лише ДВІ дитини).
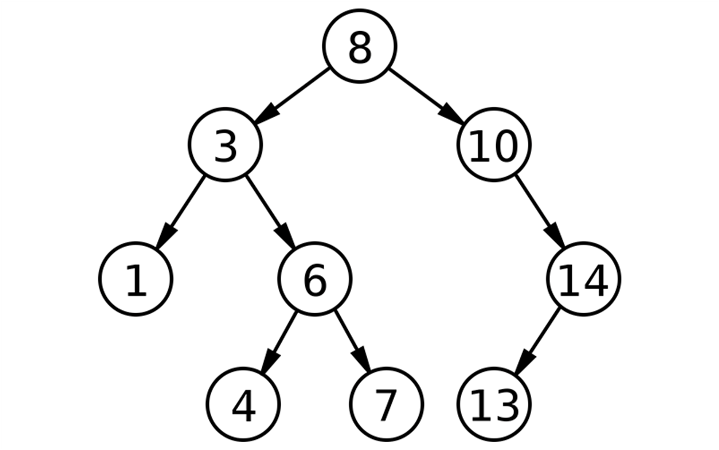
Так ось річ у тому, що виявляється, що звичайний масив зручний для зберігання даних не у всіх завданнях. Наприклад, якщо потрібно зберігати дані в відсортованому порядку і постійно щось змінювати (додавати, шукати та видаляти). У великих масивах це працює дуже довго, а ось зі збалансованими бінарними деревами пошуку (особливими видами двійкових дерев) досить швидко. Відбувається це тому, що в даному виді дерев усі операції проходять за логарифм від вхідного розміру даних (тобто аналогічно бінарному пошуку, коли ми замість 1 мільярда вгадувань потурбували Петю питаннями лише 30 разів). Думаємо, що перевага використання двійкових дерев очевидна.
Тепер щодо «обходів дерев». Зберігати інформацію в деревах навчилися, а ось підтримувати їх – ні. Для цього потрібно знати, як можна обходити дерево. Усього існує кілька способів обходу та використовується той чи інший обхід залежно від того, як дерево представлене у пам'яті. Знову ж таки, з усім цим детальніше можна ознайомитися на порталі Geek For Geeks.
Сподіваємося, що ви вже не сумніваєтеся у тому, що вивчати алгоритми корисно та цікаво.
Успіхів!
Олег Топорков





