")
")
Якщо мрієш створити свій особливий продукт штучного інтелекту (ШІ), що використовує технологію Computer Vision (CV), то це здійснімо. Але які проблеми сучасності ти хотів би розв’язати за допомогою CV?
Ми вже звикли до того, що навколо нас велика кількість сенсорних пристроїв: звичайні фотокамери, відеокамери, УЗІ, томографи й тому подібні. Всі ці пристрої створюють зображення. А до чого тут СV?
Комп’ютерний зір (computervision, CV) — підрозділ штучного інтелекту, що використовує алгоритми Maching Learning та Deep Learning для розпізнавання та тлумачення об'єктів на зображеннях і відео.
Як це працює?
Виявляється, що програми СV використовують зображення та відео, додав можливості ШІ для відтворення процесу подібного роботі людського зору.
Такі системи працюють на основі алгоритмів, навчених на великій кількості візуальних даних (дата сет). Вони розпізнають образи на «дата сет» та з їх допомогою визначають зміст, присутній на зображеннях.
Де це застосовують?
- Системи контролю доступу на основі розпізнавання облич гарантують безпеку банків, офісів компаній і т.д.
- Завдяки швидкій ідентифікації за обличчям можна скоротити час обслуговування клієнта.
- CV дає змогу побачите, що людина може не помітити. В медицині — це аналіз рентгенівських та інших знімків, в промисловості — це виявлення браку.
Але, звичайно, що ми згадали лише декілька прикладів, щоб не втомлювати вас довгим списком застосування CV у сучасному світі.
Які можливості СV використовують наші студенти?
Ось цей розділ сподіваємося вас зацікавить. Розглянемо три студентських наукових проєкти, які виконуються під керівництвом доцента кафедри інформатики Олени Яковлевої.
Для цього на початку згадаємо про три визначальні функції, за допомогою яких CV може оброблять зображення і повертати інформацію користувачам.
- Ідентифікація Об'єктів.

Проєкт «Розпізнавання медичних масок на обличчях людей»
Так, існують системи, що вміють реєструвати, та навіть розпізнавати людину за наявності окулярів, капелюхів, вусів. А от медична маска закриває обличчя значно більше, залишаючи тільки невелику верхню частину обличчя, що є проблемою для наявних систем.
Цей проєкт було створено для формування «дата сету» пацієнтів у медичних масках, щоб потім розв'язувати глобальніші задачі, пов’язані з розпізнаванням маски на обличчі, чи навіть виявлення тієї ж самої людині в масці, або без неї.
За результатами проєкту було сформовано «дата сет» з більш ніж 13 тисячами фото та була навчена модель виявлення маски на обличчі людини.
Проєкт є навчальним, розроблений студентом Вадимом Ардасовим.
Використовувалась мова програмування Python, бібліотеки Dlib, OpenCV, TensorflowwithKeras, Skilit-learn.
- Оптичне розпізнавання символів.

Проєкт «Розпізнавання цінників товарів»
Згадайте, чи ви часто стикалися с тим, що покупець на касі відчуває незадоволення від того, що ціна на чеку не збігається з ціною на поличці? Тому інколи виникає потреба порівняти ціни на продукти. Або, як у прикладі, перевірити штрих-код, який не відповідає ціні товару.
- Алгоритм цього програмного застосунку спочатку знаходить та розпізнає штрих-код. Для цього існує бібліотека ZXing, яка допомагає декодувати штрих-код (навіть на поганих фото), аналізує зображення по піксельне і видає тип коду, та його числове значення.
- А вже іншим кроком йде розпізнавання тексту та ціни для порівняння, за допомогою бібліотеки Tesseract.
Це спільний проєкт з IT компанією SYTOSS, який розроблений студентом Андрієм Ковтуненко.
Використовувалась мова С++ та бібліотеки OpenCV, Libtorch, ZXing, Tesseract.
- Класифікація об'єктів.
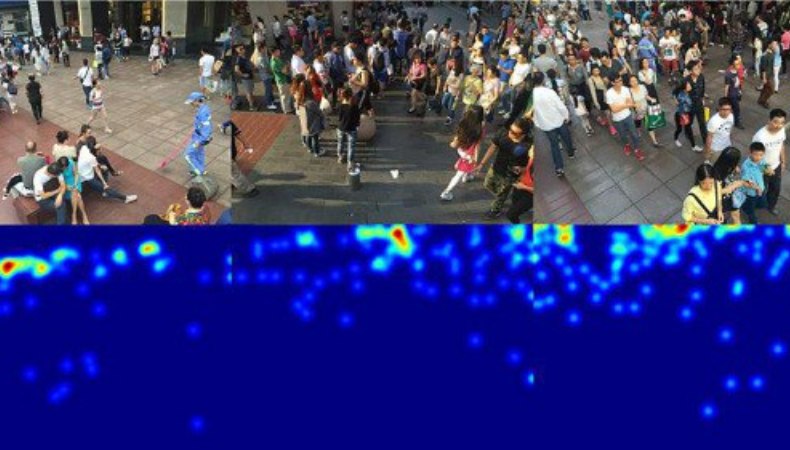
Проєкт «Підрахунок людей у натовпі»
Уявіть, що черга перед касою у торговому центрі переповнена. Або метро, переповнене о 7 ранку настільки, що вже нагадує китайське метро у годину пік.
Тоді з’являється потреба у підрахунку людей у натовпі, щоб відкрити нову касу, або запустити додаткові поїзди.
Точна оцінка кількості об’єктів на одному зображенні — це складна, але важлива задача, що застосовується в багатьох додатках, пов’язаних з міським плануванням та громадською безпекою.
В цьому проєкті було використано глибокі згорткові нейронні мережі.
Це такий алгоритм CV, який може зберігати інформацію про кожне аналізоване зображення і з плином часу ще більше підвищувати точність.
Проєкт створила студентка Тетяна Норматова.
Використовувалась мова Python та бібліотеки PyTorch, OpenCV.
Результати цього проєкту були апробовані:
- XI-й Міжнародна науково-практична конференція «Freeand Open Source Software»;
- Міжнародна науково-технічна конференція «Інформатика, управління та штучний інтелект»
- 24-й Міжнародний молодіжний форум «Радіоелектроніка та молодь у XXI столітті», де проєкт посів II місце.
Отже, наостанок хороша новина.
Усі роботи активно продовжують досліджуватись на кафедрі Інформатики у роботах студентів, тому ви маєте усі можливості долучитися та внести свій внесок до цих корисних й таких необхідних рішень сучасності.
Розвиток комп'ютерного зору практично шалено прискорюється! На кафедрі Інформатики ХНУРЕ він давно вже став основним науковим напрямом. І це тільки початок! Ми плануємо розкрити багато цікавих розробок у наших майбутніх статтях. Слідкуйте за оновленнями!
Ірина Кириченко





