")
")
Помните этот прикол из Снапчата (мобильное приложение обмена сообщениями с прикреплёнными фото и видео), когда камера находила «лица» в темноте и накладывала на них маски, а на деле там ничего не было? Это отличный пример ошибки в распознавании объектов от «умной» камеры. Сейчас поговорим о том, как AI (Artificial intelligence) научился справляться с подобными задачами, распознавая предметы, тексты и даже людей.
Основная идея компьютерного зрения - научить программу (да-да, обычно AI, искусственный интеллект(ИИ) - это всего-то небольшая программка) находить закономерности на картинках и относить их к определённой группе. Но как объяснить компьютеру, что делать? Например, человек сразу понимает, что перед ним котик, а не самолет, потому что у него УЖЕ есть образы этих вещей в голове. Он видел сотни котиков и самолетов, и запросто может отличить их друг от друга. Улавливаете суть?

ОБУЧЕНИЕ НЕЙРОННОЙ СЕТИ
Компьютер «учат» также, как и маленького ребенка – показывают, называют предмет, и повторяют процесс много раз. Когда вы слышите фразу «обучение нейронной сети», что это обозначает? В нашем случае имеется в виду, что мы даем программе картинку, а она смотрит на нее, думает, и отвечает, что на ней находится, и только потом мы показываем программе правильный ответ. В зависимости от того, угадала она или нет, программа сама подстраивает свои алгоритмы, чтобы не ошибиться в следующий раз.
Для обучения машин программисты придумали, как имитировать человеческие нейронные сети (мозг) на компьютере. Нейроны живых организмов обычно принимают на вход один сигнал от рецепторов, разделяют его и обрабатывают, а затем отправляют дальше уже гораздо большему количеству нейронов. Нейроны для программы – это, грубо говоря, обычные функции, но довольно сложно устроенные, и выполняют они ту же функцию, что и человеческие.
КАК ПРОГРАММА ВИДИТ КАРТИНКИ?
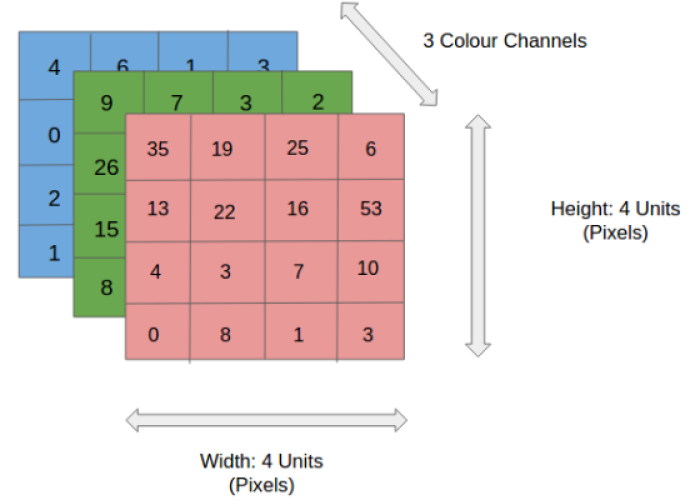
Давайте «копнем» глубже. Компьютер воспринимает картинки в виде чисел – каждому пикселю, минимальной цветной точке, соответствует число от 0 до 255. Если картинка черно-белая, пикселю просто присваивается число в зависимости от его «светлости» и «темности» – интенсивности цвета. Чем темнее – тем больше число. И получается, что фото – это вектор (массив) из чисел.
В случае с цветными фото все не намного сложнее: для экранов гаджетов информация о цвете хранится в RGB: R – отвечает за интенсивность красного цвета данного пикселя (red), G– зеленого (green), B–синего (blue). Различные комбинации интенсивности этих трех основных цветов дают разный цвет пикселя на картинке. Так вот, для представления цветных картинок берется три таких вектора с числами – для каждого цвета по одному. Выходит, что разница между ЧБ и цветным фото для программы состоит в основном во времени, которое уходит на их обработку.
КАК ПРОГРАММА ОБРАБАТЫВАЕТ КАРТИНКИ?
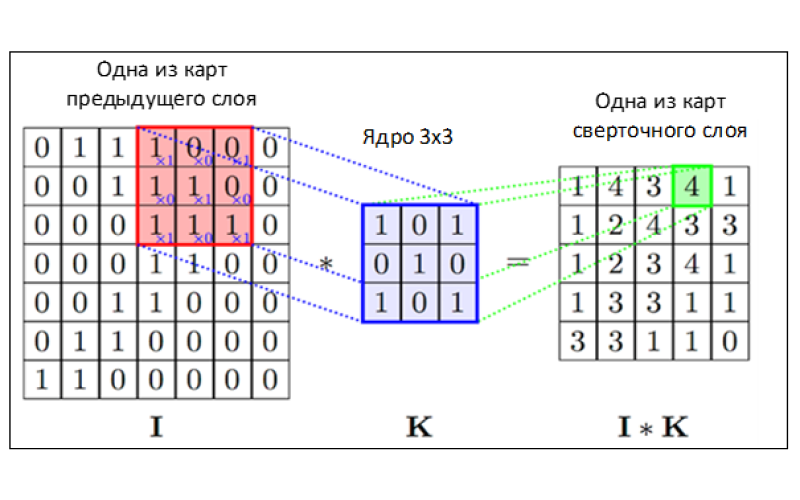
Рассмотрим примерный алгоритм обработки картинки программой.
1. Выбирается размер участка А х А пикселей.
2. Рассматривается участок такого размера в одном из углов картинки, где, грубо говоря, координата (0;0).
3. В зависимости от алгоритма, выбирается один из вариантов:
1)пиксель с самым большим числом (то есть самый яркий, самый заметный и значимый пиксель);
2)среднее/медиану/моду от значений всех охваченных пикселей;
3)умножает участок на одно из так называемых ядер свертки (на деле это просто определенная матрица с числами);
4)или же использует все по порядку.
4. Полученное число записывается в новую «картинку».
5. После чего изменяется область осмотра участка на один пиксель вперед, т.е начиная с координаты (0;1), и так весь ряд (0;2), (0;3)…, а затем происходит перемещение вниз, на участок (1;0), и точно так же – до конца ряда.
6. В итоге у нас получается картинка меньшего размера, но содержащая только самые важные пиксели предыдущей картинки.
7. Процесс повторяется уже с новой картинкой.
Таким образом, программа всегда проверяет и выделяет для себя основные признаки, в какой-то момент останавливается и говорит ответ – обозначая то, что находится на фото.
И ЧТО В ИТОГЕ?
Ура, мы разобрались (надеюсь) в алгоритме работы с картинками. Теперь нам нужно собрать много разных картинок одного и того же предмета, и разделить их на 2 части – одну для тренировки программы, а другую для проверки того, насколько хорошо мы натренировали алгоритм. И вот как раз на стадии запуска тестовых (проверочных) данных мы уже не говорим «нейронке» правильные ответы, а только смотрим результат обработки (исследования) картинки программой. Если алгоритм работает хорошо – ура, у нас получилось обучить программу и теперь она обладает «интеллектом» ребенка лет четырех.
А В ХНУРЭ ЭТОМУ УЧАТ?
Как студент специальности 122 «Информационные технологии и искусственный интеллект» могу сказать, что очень даже учат. Не с первого курса, конечно, но начиная со второго «матчасти» будет становиться все меньше, а практических предметов по машинному обучению и интеллектуальным системам – все больше. Преподаватели в этом интересном деле всегда только рады помогать студентам, которые «рвутся» к новым знаниям, что я считаю большим плюсом обучения на кафедре ИИ.
P.S.: дисклеймер для тех, кто хорошо разбирается в нейронных сетях – материал рассчитан на новичков, поэтому информация может показаться неточной или недостаточной. Подобное изложение материала сделано намеренно для упрощения восприятия.
Рита Казьмина
.





